10x Genomics Xenium
This tutorial is for visualizing 10x Genomics Xenium datasets.
In order to visualize your Xenium dataset in BellaVista, you will need to create a dataset-specific JSON configuration file containing paths to the Xenium outputs for your dataset. These output files will be processed to generate visualization files for BellaVista. Creating these visualization files will take a few minutes but only need to be created once. For subsequent runs, create_inputs can be set to False.
Configuration JSON file structure
{
"system": "xenium",
"data_folder": "/path/to/Xenium_dataset_outs",
"create_bellavista_inputs": true,
"visualization_parameters": {
"plot_image": true,
"plot_transcripts": true,
"plot_allgenes": true,
"genes_visible_on_startup": false,
"plot_cell_seg": true,
"plot_nuclear_seg": true
},
"input_files": {
"transcript_filename": "transcripts.parquet",
"images": "morphology.ome.tif",
"z_plane": 0,
"cell_segmentation": "cell_boundaries.parquet",
"nuclear_segmentation": "nucleus_boundaries.parquet"
}
}
Input file parameters (Xenium)
- transcript_filename: string
relative path to a Parquet or CSV file containing transcript spatial locations. If None, no transcripts will be processed
- images: string or 1D array of strings
relative path to image file(s). Must be an OME-TIFF or TIFF file. If None, no images will be processed
When visualizing a single image, provide the file path as a string. For multiple images, pass them as a list of filenames. For example, use "DAPI.tif" for a single image or ["DAPI.tif", "PolyT.tif"] for multiple images
- z_plane: integer, default=0
z-plane of image to be visualize. If None, the first z-plane will be used
- cell_segmentation: string
relative path to Parquet or Zarr file containing cell segmentations. If None, no cell segmentations will be processed
- nuclear_segmentation: string
relative path to Parquet or Zarr file containing nuclear segmentations. If None, no nuclear segmentations will be processed
Important
All input file paths must be relative paths to data_folder
Note
If you are missing some input files, remove those input file parameters from the JSON file. BellaVista will skip the visualization of these data.
For example, if you do not have nuclear segmentations, the input file parameters in your JSON file might look like this:
"input_files": {
"transcript_filename": "transcripts.parquet",
"images": "morphology.ome.tif",
"z_plane": 0,
"cell_segmentation": "cell_boundaries.parquet"
}
General parameters
- system: string
Value:
"Xenium"
The input is not case-sensitive, so values "xenium", "Xenium", and "XENIUM" are treated equivalently- data_folder: string
The path to the folder where the dataset output files are stored. BellaVista visualization files will be saved in a new folder named
BellaVista_outputwithin the data_folder.- create_bellavista_inputs: boolean, default=true
Specifies whether to generate the necessary visualization files for BellaVista. It should be set to
truewhen loading the data for the first time. It can be set tofalsein later runs, as the files will already have been created.If set to
trueand the visualization files already exist from a previous run, BellaVista will skip recreating those files and only generate any missing ones.
Visualization parameters
- plot_image: boolean, default=false
Display image(s)
- plot_transcripts: boolean, default=false
Plot spatial coordinates of gene transcripts
- plot_allgenes: boolean, default=true
Plot transcripts for all gene IDs. If set to
false, only the gene IDs specified inselected_geneswill be plotted- genes_visible_on_startup: boolean, default=false
Controls the visibility of all gene layers at startup. If set to
false, the gene layers will be hidden
Setting this option to false improves navigation performance. Gene layers can be shown later using the toggle visibility feature.
- selected_genes: 1D array of strings, default=None
Specifies the gene IDs whose transcripts will be plotted. If None, transcripts for all genes will be plotted
- plot_cell_seg: boolean, default=false
Plot cell segmentation
- plot_nuclear_seg: boolean, default=false
Plot nuclear segmentation
- transcript_point_size: float, default=1
Size of the points representing individual transcript coordinates
- contrast_limits: tuple array of integers, default=None
Range of values [0, 65535] used to set the contrast limits for the displayed image(s)
- rotate_angle: integer, default=0
Rotation angle in degrees, within the range [0, 360], by which to rotate the data
Loading BellaVista
Once your JSON is correctly configured for your dataset, you can run BellaVista in the terminal:
Replace
my_dataset.jsonwith the filename of the JSON you created. The JSON file argument should contain the file path to your JSON file.
bellavista my_dataset.json
Note
It will take a few minutes to create the required data files. The terminal will print updates & have progress bars for time consuming steps.
Once loaded, you should see a napari window displaying your data. Now, you can interactively move around the napari canvas to explore the data. Try zooming in & out, toggling layers on & off to see different spatial patterns!
Tip
To visualize a single layer, and hide all other layers, Option/Alt-click on the visibility button (the eye, to the left of the layer name). Check out Helpful napari tips in the FAQ for more tips!
Refer to the tutorial below for a step-by-step guide on running BellaVista with a sample dataset and JSON.
If you encounter any issues, please check the FAQ. If you're experiencing issues not addressed in the FAQ, please check the open issues or open a new issuein our GitHub repository. You can also leave any feedback here!
Getting Started (with sample data)
Download sample data
Download sample data from Zenodo: Xenium mouse brain dataset (Replicate 3) https://zenodo.org/records/14279832

Load BellaVista
Run BellaVista from the command line with the Xenium sample data:
Replace
/path/to/with the actual path to the Xenium sample data folder.
$ bellavista --xenium-sample /path/to/xenium_mouse_brain_rep3
Note
It will take a few minutes to create the required data files. The terminal will print updates & have progress bars for time consuming steps.
Once successfully loaded, you should see the message Data Loaded! in the terminal.
A napari window should appear displaying the data similar to the image below:
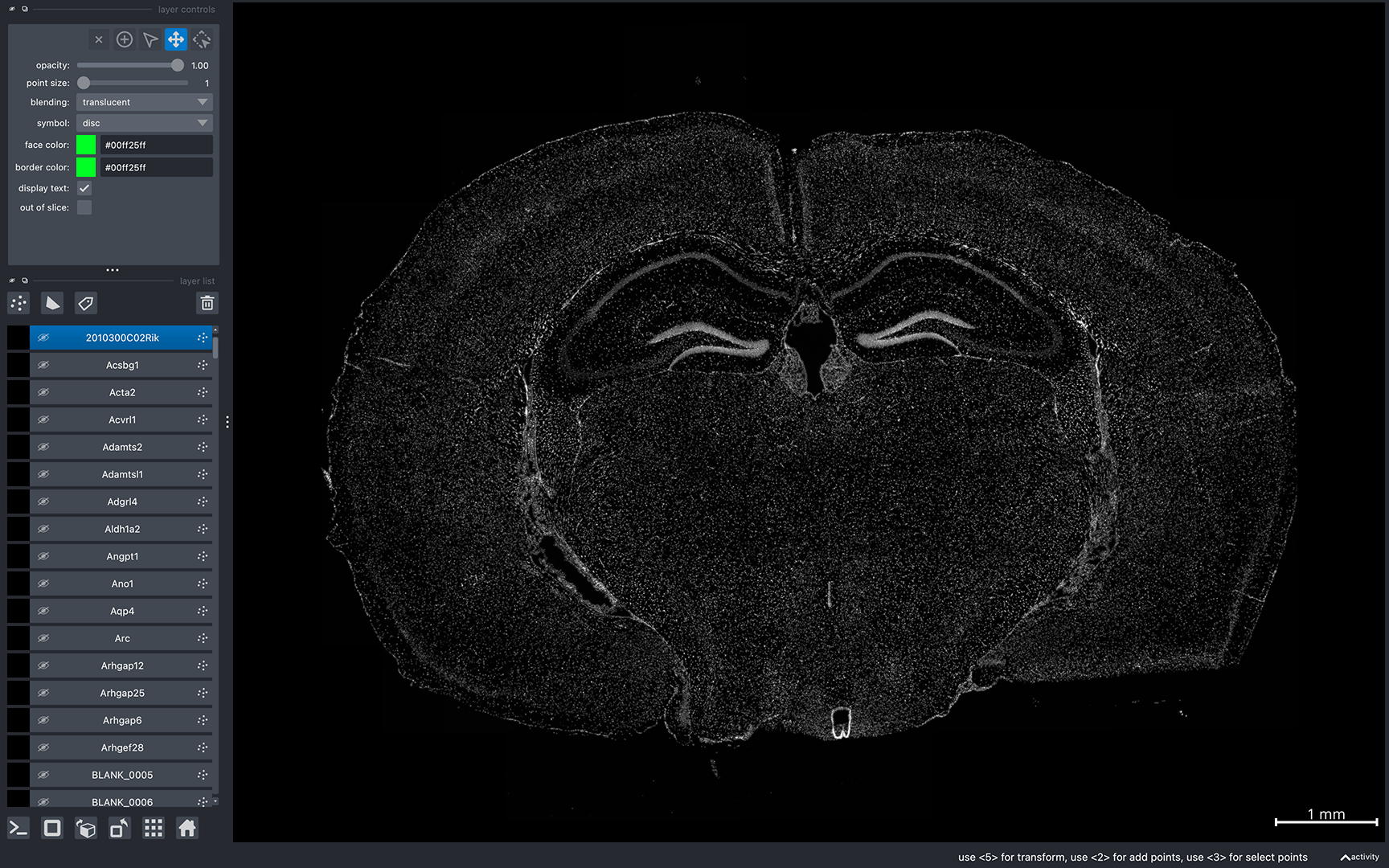
Now, you can interactively move around the napari canvas to explore the data!
Try zooming in & out, toggling layers on & off to see different spatial patterns:


Tip
To visualize a single layer, and hide all other layers, Option/Alt-click on the visibility button (the eye, to the left of the layer name). Check out Helpful napari tips in the FAQ for more tips!
Note
Gene colors are assigned randomly every time BellaVista is launched. So, the gene colors displayed in your window will be different from the image above. See Helpful napari tips in the FAQ for information on how to configure gene colors and other customizable visualization options.
To reproduce the same colors every time you launch BellaVista, see Creating your own figures! in the Figure Guide.
For an exact reproduction of the two screenshots above, please refer to the figure guide: Reproducing sample figures (Xenium)
If you encounter any issues, please check the FAQ. If you're experiencing issues not addressed in the FAQ, please check the open issues or open a new issuein our GitHub repository. You can also leave any feedback here!